Kafka está morto, viva Kafka
- pedrobusko
- 11 de jul. de 2025
- 12 min de leitura
Este é um artigo traduzido originalmente publicado por Richard Artoul em 25/07/2023 no blog da WarpStream: "Kafka is dead, long live Kafka". Resumo
WarpStream é uma plataforma de streaming de dados compatível com o protocolo Apache Kafka®, construída diretamente sobre o S3. É entregue como um binário Go único stateless, dispensando discos locais para gerenciar, brokers para rebalancear e ZooKeeper para operar. O WarpStream é de 5 a 10 vezes mais barato que o Kafka na nuvem, pois os dados são transmitidos diretamente de e para o S3, em vez de usar redes entre zonas, o que pode representar mais de 80% do custo de infraestrutura de uma implantação do Kafka em escala.
Se você quer apenas colocar a mão na massa, pode experimentar nossa demonstração em menos de 30 segundos.
$ curl https://console.warpstream.com/install.sh | bash
$ warpstream demoCaso contrário, continue lendo!
Kafka está morto, viva Kafka
Provavelmente você teve uma reação forte ao título deste post. Em nossa experiência, o Kafka é uma das tecnologias mais polarizadoras no setor de dados. Algumas pessoas o odeiam, outras o elogiam, mas quase todas as empresas de tecnologia o utilizam.
O Apache Kafka® foi disponibilizado pela primeira vez em código aberto em 2011 e rapidamente se tornou a infraestrutura padrão para a construção de arquiteturas de streaming. O famoso post do Jay Kreps, The Log, ainda é um dos meus favoritos, pois explica por que a abstração de log distribuído que o Kafka oferece é tão poderosa.
Mas não estamos mais em 2011. Muita coisa mudou na forma como construímos software moderno, principalmente uma grande migração para ambientes de nuvem, e ainda assim o Kafka permaneceu mais ou menos o mesmo. Muitas organizações conseguiram "levantar e transferir" o Kafka para seus ambientes de nuvem, mas, sejamos honestos, ninguém está realmente satisfeito com o resultado. O Kafka é caro, complexo e difícil de executar para a maioria das organizações que o utilizam.
O Kafka em si não é o problema. É um ótimo software, adequado ao ambiente para o qual foi criado: os data centers do LinkedIn em 2011. No entanto, é excepcionalmente inadequado para cargas de trabalho modernas por dois motivos:
Economia da nuvem: por definição, a estratégia de replicação do Kafka gerará enormes custos de largura de banda entre zonas de disponibilidade.
Sobrecarga operacional – executar seu próprio cluster Kafka requer literalmente uma equipe dedicada e ferramentas personalizadas sofisticadas.
Vamos abordar o Kafka no restante deste post, mas tenha em mente que tudo o que estamos dizendo sobre o Kafka se aplica igualmente a qualquer sistema similar que armazene dados em discos locais (mesmo que brevemente), independentemente da linguagem de programação em que ele for implementado.
Kafka-nomics
O diagrama abaixo descreve um cluster Kafka típico de 3 zonas de disponibilidade:

Cada GiB de dados produzido deve ser gravado entre zonas em 2/3 do tempo 1 , e posteriormente replicado pelo líder da partição para os seguidores nas outras duas zonas por motivos de durabilidade e disponibilidade. Cada vez que um GiB de dados é transferido entre zonas, o custo é de US$ 0,02 2 , sendo US$ 0,01 para saída na zona de origem e US$ 0,01 para entrada na zona de destino.
US$ 0,02*⅔ + US$ 0,02*2 == US$ 0,053 para cada GiB de dados transmitidos pelo seu cluster Kafka no melhor cenário 3 . O custo de armazenar um GiB de dados no S3 por um mês é de apenas US$ 0,021 4 , portanto, pelo mesmo preço de copiar dados de um produtor para um consumidor via Kafka, você poderia armazenar esses dados no S3 por mais de dois meses . Na prática, para qualquer cluster Kafka com throughput substancial, os custos de hardware são insignificantes, já que 70-90% do custo da carga de trabalho são apenas taxas de largura de banda entre zonas. A Confluent também tem um bom artigo sobre esse problema .
É importante ressaltar que esse problema de largura de banda entre AZs é fundamental para o funcionamento do Kafka. O Kafka foi projetado para ser executado nos data centers do LinkedIn, onde os engenheiros de rede não cobravam dos desenvolvedores de aplicativos pela movimentação de dados. Mas hoje, a maioria dos usuários do Kafka o executa em uma nuvem pública, um ambiente com restrições e modelos de custo completamente diferentes. Infelizmente, a menos que sua organização possa se comprometer com dezenas ou centenas de milhões de dólares por ano em gastos com nuvem, não há como escapar da física desse problema.
Não se trata apenas de uma questão de taxa de transferência; mesmo um cluster Kafka de baixa taxa de transferência com retenção longa pode ter grandes requisitos de armazenamento. Nesse caso, a abordagem do Kafka de replicar três vezes os dados em SSDs locais caros custa cerca de 10 a 20 vezes mais (5 por GiB) do que usar armazenamento de objetos como o S3, considerando o melhor cenário de 100% de utilização do disco.
SRE acidental
A maioria dos desenvolvedores tem contato com o Apache Kafka® pela primeira vez porque têm um problema real que desejam resolver. No entanto, antes de começarem a resolver seus problemas, precisam aprender sobre:
Kafka (brokers, coordenadores, marcas d'água, etc.)
ZooKeeper (ou KRaft)
Eleições de líderes
Partições (quantas partições eu preciso? Não está claro, mas é melhor acertar porque você nunca poderá alterá-las!)
Grupos de consumidores
Rebalance
Ajuste de broker
Ajuste de cliente
etc
O "data plane" (brokers) e o "control plane" baseado em consenso (brokers, ZooKeeper, etc.) do Kafka são executados diretamente em SSDs locais que devem ser gerenciados com competência e cuidado. Na prática, clusters Kafka auto-hospedados exigem uma equipe dedicada de especialistas e uma quantidade significativa de ferramentas personalizadas antes mesmo que operações básicas, como substituição de nós e dimensionamento de clusters, possam ser realizadas com segurança e confiabilidade. Por exemplo, a ferramenta de reatribuição de partições integrada ao Apache Kafka não consegue nem gerar planos para o descomissionamento de brokers quando (inevitavelmente) ocorre uma falha de hardware:
A ferramenta de reatribuição de partições ainda não tem a capacidade de gerar automaticamente um plano de reatribuição para brokers em descomissionamento. Portanto, o administrador precisa elaborar um plano de reatribuição para mover a réplica de todas as partições hospedadas no broker a ser descomissionado para os demais brokers. Isso pode ser relativamente trabalhoso, pois a reatribuição precisa garantir que todas as réplicas não sejam movidas do broker em descomissionamento para apenas um outro broker.
Em muitos casos, transferir o gerenciamento do cluster para um provedor de hospedagem como o AWS MSK nem sequer resolve o problema da sobrecarga operacional. Por exemplo, a documentação do MSK sobre como rebalancear um cluster (uma operação bastante rotineira) apenas vincula à documentação do Apache Kafka , que envolve a edição manual de JSON para especificar quais partições devem ser migradas para quais brokers, e inclui comentários úteis como:
A ferramenta de reatribuição de partições não tem a capacidade de estudar automaticamente a distribuição de dados em um cluster Kafka e mover partições para obter uma distribuição de carga uniforme. Portanto, o administrador precisa descobrir quais tópicos ou partições devem ser movidos.
Existem soluções de código aberto, como o Cruise Control , que podem ajudar a aliviar esse fardo, mas esse é mais um conjunto de conceitos que precisam ser aprendidos, serviços que precisam ser implantados e monitorados, e arestas que precisam ser enfrentadas. O Cruise Control em si é uma aplicação JVM que depende do Apache Kafka e do ZooKeeper. Não é uma solução tão leve.
Infelizmente, em muitos casos, os desenvolvedores decidem resolver um problema de negócios e acabam se tornando SREs do Kafka.
S3 é tudo o que você precisa
Os altos custos de utilização do Apache Kafka® (tanto em dólares quanto em horas de engenharia) significam que, atualmente, as empresas só podem utilizá-lo para seus casos de uso de maior valor, como detecção de fraudes e CDC. O custo inicial é simplesmente alto demais para qualquer outra coisa.
Quando estávamos na Datadog, construímos o Husky, um banco de dados colunar desenvolvido especificamente para dados de observabilidade, que rodava diretamente sobre o S3. Quando terminamos, tínhamos um data lake (em sua maioria) sem estado e com escalonamento automático, extremamente econômico, que nunca ficava sem espaço em disco e era fácil de operar. Quase da noite para o dia, nossos clusters do Kafka pareciam antigos em comparação.
Os volumes de largura de banda do Kafka na Datadog foram medidos em GiB/s de dois dígitos, e o armazenamento do broker foi medido em PiBs de NVMEs 6 . Manter esse nível de infraestrutura usando Kafka de código aberto, ferramentas personalizadas e VMs simples não foi tarefa fácil. Felizmente, as equipes de engenharia responsáveis na Datadog eram extremamente competentes e fizeram o projeto funcionar, mas mesmo após muitos anos de investimento, a automação simplesmente não conseguiu competir com os milhões de horas de engenharia investidas para tornar sistemas como o S3 extremamente robustos, escaláveis, econômicos e elásticos .
Em geral, grandes cargas de trabalho de armazenamento executadas em ambientes de nuvem não têm chance de competir com a economia, confiabilidade, escalabilidade e elasticidade do armazenamento de objetos . É por isso que tecnologias de "big data" como Snowflake e Databricks nem tentam. Em vez disso, elas se apoiam na economia da nuvem, projetando seus sistemas do zero com base no armazenamento de objetos comoditizado.
Empresas como Uber, Datadog e muitas outras fizeram o Kafka funcionar para elas, apesar de todas as suas falhas. Mas existem tantos problemas interessantes que nunca serão resolvidos se a implementação atual do Kafka continuar sendo a barreira de entrada. É por isso que nos importamos com esse espaço e nos propusemos a construir algo que tornasse a infraestrutura de streaming de dados tão acessível quanto o S3.
Se pudéssemos construir um sistema semelhante ao Kafka diretamente sobre o S3, resolveríamos dois dos principais problemas do Kafka de uma só vez; os custos seriam reduzidos drasticamente e a maioria das dores de cabeça operacionais tradicionais do Kafka desapareceriam da noite para o dia. Nenhum grande provedor de nuvem cobra pelos custos de rede entre VMs e armazenamento de objetos, e a AWS emprega literalmente centenas de engenheiros cuja única função é garantir que o S3 funcione de forma confiável e escalável infinitamente, para que você não precise se preocupar.
Claro, é mais fácil falar do que fazer, e há uma boa razão para que ninguém tenha feito isso ainda: descobrir como construir uma infraestrutura de streaming de baixa latência sobre um meio de armazenamento de alta latência como o S3, e ainda fornecer a semântica completa do protocolo Kafka, sem introduzir nenhum disco local, é um problema muito complicado!
Então nos perguntamos: "Como seria o Kafka se fosse redesenhado do zero hoje para ser executado em ambientes de nuvem modernos, diretamente sobre o armazenamento de objetos, sem discos locais para gerenciar, mas ainda tendo que dar suporte ao protocolo Kafka existente?"
WarpStream é a nossa resposta para essa pergunta.
Apresentando o WarpStream
WarpStream é uma plataforma de streaming de dados compatível com o protocolo Apache Kafka® que roda diretamente sobre qualquer repositório de objetos de commodities (AWS S3, GCP GCS, Azure Blob Storage, etc.). Ela não gera custos de largura de banda entre AZs, não precisa gerenciar discos locais e pode ser executada completamente dentro da sua VPC.
É muita coisa para digerir, então vamos analisar comparando a arquitetura do WarpStream com a do Kafka:
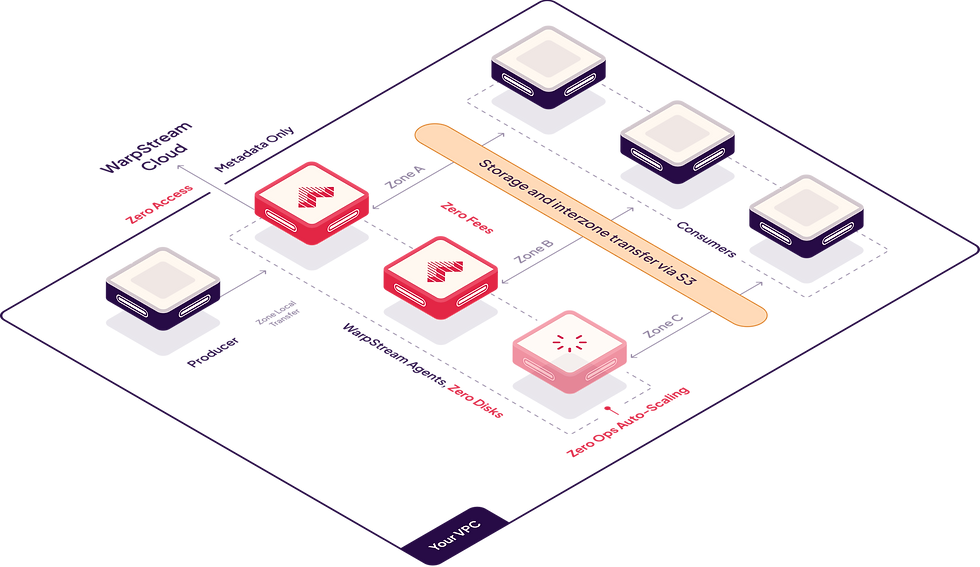
Em vez de brokers Kafka, o WarpStream possui "Agentes". Os agentes são binários Go sem estado (sem JVM!) que falam o protocolo Kafka, mas, diferentemente de um broker Kafka tradicional, qualquer agente WarpStream pode atuar como "líder" para qualquer tópico, confirmar offsets para qualquer grupo de consumidores ou atuar como coordenador do cluster. Nenhum agente é especial, portanto, escaloná-los automaticamente com base no uso da CPU ou na largura de banda da rede é trivial.
Como conseguimos isso se o Apache Kafka exige a execução do Apache ZooKeeper (ou KRaft) e vários brokers com estado, SSDs locais e replicação?
Separamos o armazenamento e a computação (descarregando dados para o S3)
Separamos os dados dos metadados (descarregando os metadados para um armazenamento de metadados personalizado)
Descarregar todo o armazenamento para um armazenamento de objetos como o S3 permite que os usuários dimensionem facilmente o número de Agentes WarpStream em resposta a alterações na carga, sem necessidade de rebalanceamento de dados . Isso também permite uma recuperação mais rápida de falhas, pois qualquer solicitação pode ser repetida imediatamente em outro Agente. Além disso, elimina praticamente todos os pontos críticos, onde alguns agentes Kafka teriam uma carga significativamente maior do que outros devido à quantidade desigual de dados em cada partição. Isso significa que você pode se livrar do rebalanceamento manual de partições e não precisa aprender soluções complexas como o Cruise Control.
O outro pilar do design do WarpStream é a separação de dados dos metadados, assim como um data lake moderno faz. Armazenamos os metadados de cada "Cluster Virtual" do WarpStream em um banco de dados de metadados personalizado, criado do zero para resolver exatamente esse problema da maneira mais eficiente e econômica possível. Estamos tão confiantes na eficiência do nosso armazenamento de metadados que hospedaremos Clusters Virtuais do WarpStream gratuitamente para você .
Você pode ler mais sobre a arquitetura do WarpStream em nossa documentação , mas, para resumir: o WarpStream transfere todos os problemas complexos de replicação, durabilidade e disponibilidade de dados para um bucket de armazenamento de objetos, para que você nunca precise se preocupar com isso, e todos os seus dados permanecem dentro da sua conta na nuvem . Os únicos dados que saem da sua conta na nuvem com o WarpStream são os metadados da carga de trabalho necessários para o consenso, como a ordem dos lotes nas suas partições.
Profissionais modernos que desejam introduzir pipelines de streaming de dados em larga escala em sua infraestrutura hoje não têm muitas opções. Eles precisam investir muito dinheiro e criar uma equipe dedicada de engenheiros cuja única função é operar o Kafka, ou pagar um fornecedor por uma solução hospedada e gastar ainda mais , tornando muitos de seus casos de uso de streaming economicamente inviáveis.
Acreditamos que o WarpStream pode fornecer uma opção melhor que aproveita a nuvem como um ponto forte em vez de um ponto fraco, e abre um novo conjunto de possibilidades no mundo do streaming de dados.
Mas você não precisa acreditar apenas em nós, nós trouxemos recibos! A imagem abaixo mostra os custos de rede entre zonas de toda a nossa conta na nuvem (medidos usando o excelente vantage.sh ), incluindo a carga de trabalho de streaming contínuo que executamos em nosso ambiente de teste. Essa carga de trabalho produz continuamente 140 MiB/s de dados e os consome com três consumidores dedicados, totalizando 560 MiB/s em transferência contínua de dados.
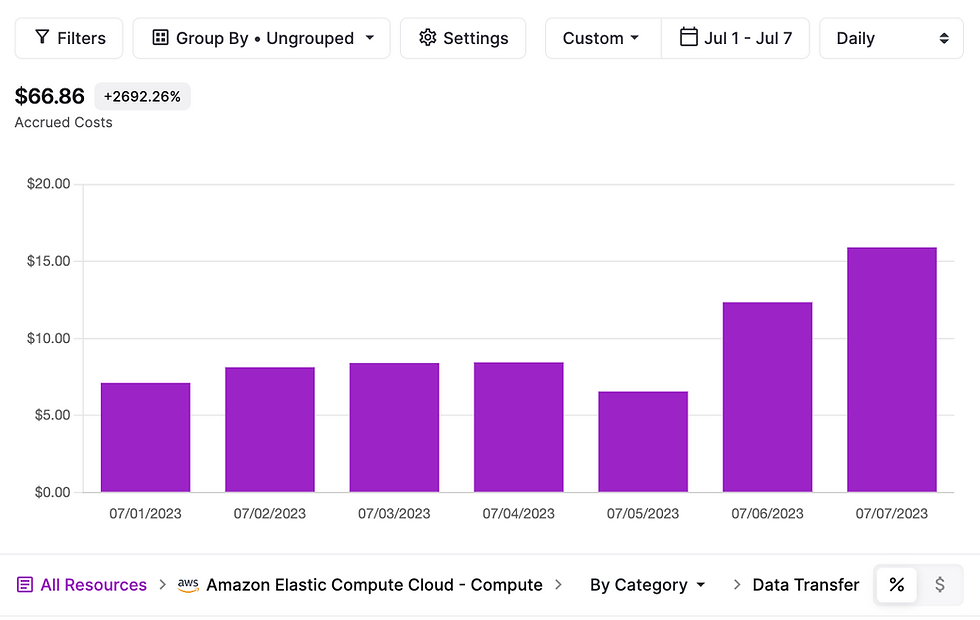
Você pode ver que temos uma média de < US$ 15/dia em taxas de rede entre zonas, enquanto a mesma carga de trabalho executada usando um cluster Kafka custaria 0,14 GiB US$ 0,053/GiB 60 60 24 == US $ 641 por dia somente em taxas de rede entre zonas.
Não substituímos apenas esses custos de rede entre zonas por custos de hardware ou da API S3. Essa mesma carga de trabalho custa menos de US$ 40/dia em custos operacionais da API S3:
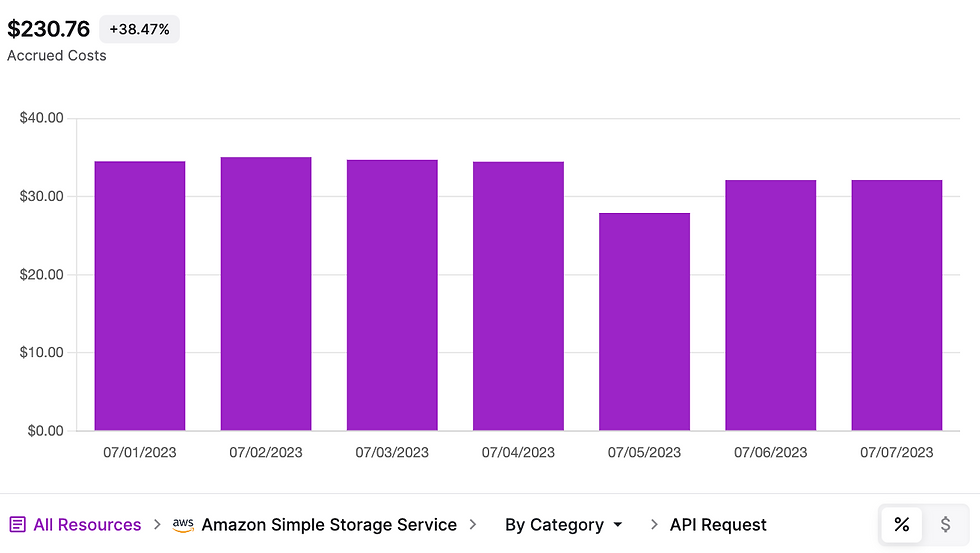
Ele também requer apenas 27 vCPUs de hardware de agente/VMs.
Em termos de custo total de propriedade, o WarpStream reduzirá o custo da maioria das cargas de trabalho do Kafka em 5 a 10 vezes. Por exemplo, aqui está uma comparação do custo de execução de uma carga de trabalho Kafka de 1 GiB/s sustentada em comparação com o equivalente usando o WarpStream:

A tabela acima demonstra claramente que, para cargas de trabalho de alto volume do Kafka, os custos de hardware são insignificantes, pois o custo da carga de trabalho é dominado pelas taxas de rede entre zonas. O WarpStream elimina completamente essas taxas de rede.
Claro, nem tudo são flores. Engenharia envolve compensações, e fizemos uma significativa com o WarpStream: latência. A implementação atual tem um P99 de ~400 ms para solicitações Produce, pois nunca reconhecemos dados até que eles tenham sido persistentemente persistidos no S3 e confirmados em nosso plano de controle na nuvem. Além disso, nossa latência P99 atual de dados de ponta a ponta, do produtor ao consumidor, é de cerca de 1s:
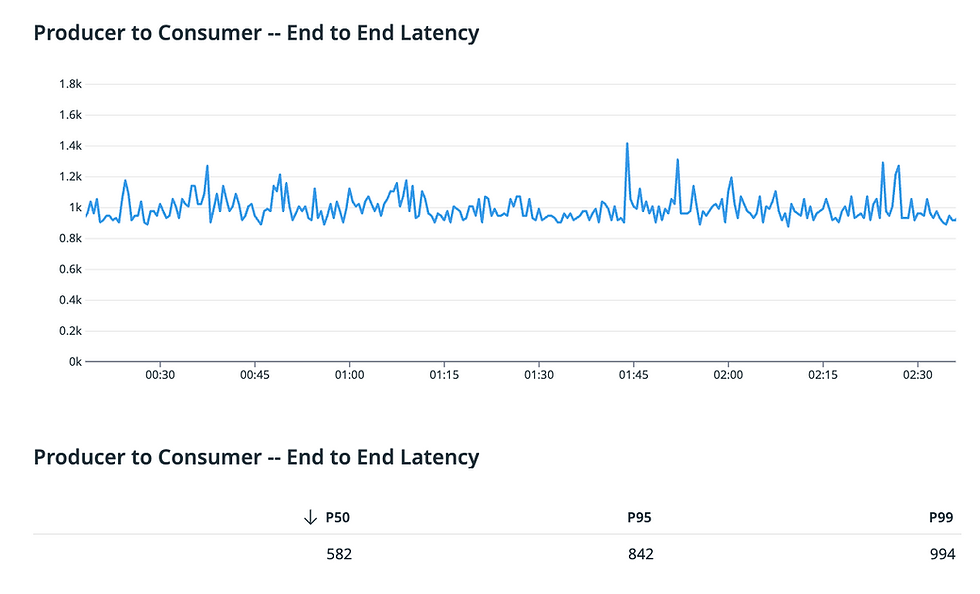
Se a sua carga de trabalho tolerar um P99 de ~1s de latência do produtor para o consumidor, o WarpStream pode reduzir seus custos totais de streaming de dados em 5 a 10 vezes por GiB, com praticamente zero de overhead operacional. Também não temos uma interface proprietária; é apenas Kafka, portanto, não há dependência de fornecedor. Por fim, o WarpStream roda em qualquer ambiente com uma implementação de armazenamento de objetos, então podemos atender às suas necessidades com S3 na AWS, GCS no GCP e Azure Blob Storage no Azure.
Se você chegou até aqui, deve ter notado que o WarpStream aborda principalmente dois dos principais problemas do Kafka: a economia da nuvem e a sobrecarga operacional. Acreditamos que há um terceiro grande problema com o Kafka: a experiência do usuário (UX) para desenvolvedores. Em nossa opinião, partições são uma abstração de nível muito baixo para programar em qualquer aplicativo de processamento de fluxo não trivial, e acreditamos que a arquitetura do WarpStream nos coloca em uma posição única para ajudar desenvolvedores a escrever aplicativos de processamento de fluxo de uma maneira inovadora, muito mais próxima de como estão acostumados a escrever aplicativos tradicionais.
Falaremos mais sobre isso em uma postagem futura do blog, mas a primeira coisa que queríamos fazer era encontrar os desenvolvedores onde eles estão e oferecer a eles uma versão melhorada de uma ferramenta com a qual eles já estão familiarizados.
Se você quer apenas colocar a mão na massa, pode experimentar nossa demonstração em menos de 30s:
$ curl https://console.warpstream.com/install.sh | bash
$ warpstream demoPorque o líder da partição está em uma zona diferente.
Consulte a seção “Transferência de dados dentro da região da AWS” .
O pior cenário é que seu cluster Kafka não esteja configurado com o recurso de busca de seguidores e você esteja pagando taxas de largura de banda entre zonas para cada um dos seus consumidores também.
(US$ 0,452/h (i3en.xlarge) 24 30)/(2500 GiB) == US$ 0,13/GiB mês. US$ 0,13 * replicação 3x == US$ 0,39/GiB mês vs US$ 0,021/GiB mês no S3
https://www.datadoghq.com/blog/engineering/introducing-kafka-kit-tools-for-scaling-kafka/
9 * i3en.6xl + ZK
($(0,04 + ((2/3) 0,02)) 60 60 24 * 365)+$223000



Comentários